The libdispatch is one of the most misused API due to the way it was presented to us when it was introduced and for many years after that, and due to the confusing documentation and API. This page is a compilation of important things to know if you're going to use this library. Many references are available at the end of this document pointing to comments from Apple's very own libdispatch maintainer (Pierre Habouzit).
My take-aways are:
-
You should create very few, long-lived, well-defined queues. These queues should be seen as execution contexts in your program (gui, background work, ...) that benefit from executing in parallel. An important thing to note is that if these queues are all active at once, you will get as many threads running. In most apps, you probably do not need to create more than 3 or 4 queues.
-
Go serial first, and as you find performance bottle necks, measure why, and if concurrency helps, apply with care, always validating under system pressure. Reuse queues by default and add more if there's some measurable benefit to it. Do not attempt to go wide by default.
-
Queues that target other (non-global) queues are fine and you can have many of those (the main point is having different labels). You can create such queues with
DispatchQueue(label:target:). -
Don't use
DispatchQueue.global(). Global queues easily lead to thread explosion: threads blocking on sleeps/waits/locks are considered inactive by the libdispatch which in turn will spawn new threads when other parts of your program dispatch. Note that it is impossible to guarantee that your threads are never going to block, as merely using the system libraries will cause it to happen. Global queues also do not play nice with qos/priorities. The libdispatch maintainer at Apple declared it "the worst thing that the dispatch API provides". Run your code on one of your custom queue instead (one of your well-defined execution context). -
Concurrent queues are not as optimized as serial queues. Use them if you measure a performance improvement, otherwise it's likely premature optimization.
-
queue.async()is wasteful if the dispatched block is small (< 1ms), as it will most likely require a new thread due to libdispatch's overcommit behavior. Prefer locking to protect shared state (rather than switching the execution context). -
Some classes/libraries are better designed as synchronous APIs, reusing the execution context from their callers/clients (instead of creating their own private queues which can lead to terrible performance). That means using traditional locking for thread-safety.
-
Locks are not as bas as people think they are. They still work extremely well to protect shared state, they are fast and keep the code synchronous which allows to avoid reentrancy problems altogether. See
OSAllocatedUnfairLockand the brand newMutextypes. -
Do not block the current thread waiting on a semaphore or dispatch group after dispatching work. This is inefficient as the kernel can't know what thread will ultimately unblock the thread. Rather, continue work asynchronously in a completion handler that is executed once the asynchronous work ends or just do the work synchronously. If you are doing XPC, synchronous message sending is fine and can be achieved with
synchronousRemoteObjectProxyWithErrorHandler(). -
Do not use
DispatchQueue.mainin non-GUI programs and frameworks. Per the<dispatch/queue.h>header: "Because the main queue doesn't behave entirely like a regular serial queue, it may have unwanted side-effects when used in processes that are not UI apps (daemons). For such processes, the main queue should be avoided". -
If running concurrently, your work items need not to contend, else your performance sinks dramatically. Contention takes many forms. Locks are obvious, but it really means use of shared resources that can be a bottle neck: IPC/daemons, malloc (lock), shared memory, I/O, ...
-
You don't need to be async all the way to avoid thread explosion. Using a small number of dispatch queues and not using
DispatchQueue.global()is a better fix. -
The complexity (and bugs) of heavy async/callback designs also cannot be ignored. Synchronous code remains much easier to read, write and maintain.
-
Utilizing more than 3-4 cores isn't something that is easy, most people who try actually do not scale and waste energy for a modicum performance win. It doesn't help that CPUs have thermal issues if you ramp up, e.g. Intel will turn off turbo-boost if you use enough cores.
-
Measure the real-world performance of your product to make sure you are actually making it faster and not slower. Be very careful with micro benchmarks (they hide cache effects and keep thread pools hot), you should always have a macro benchmark to validate what you're doing.
-
libdispatch is efficient but not magic. Resources are not infinite. You cannot ignore the reality of the underlying operating system and hardware you're running on. Not all code is prone to parallelization.
This long discussion on the swift-evolution mailing-list started it all (look for Pierre Habouzit).
- https://lists.swift.org/pipermail/swift-evolution/Week-of-Mon-20170828/date.html
- https://lists.swift.org/pipermail/swift-evolution/Week-of-Mon-20170904/date.html
Use very few queues
- https://lists.swift.org/pipermail/swift-evolution/Week-of-Mon-20170828/039368.html
- https://lists.swift.org/pipermail/swift-evolution/Week-of-Mon-20170828/039405.html
- https://lists.swift.org/pipermail/swift-evolution/Week-of-Mon-20170828/039410.html
- https://lists.swift.org/pipermail/swift-evolution/Week-of-Mon-20170828/039420.html
- https://lists.swift.org/pipermail/swift-evolution/Week-of-Mon-20170828/039429.html
- https://lists.swift.org/pipermail/swift-evolution/Week-of-Mon-20170904/039461.html
Go serial first
- https://twitter.com/pedantcoder/status/1081658384577835009
- https://twitter.com/pedantcoder/status/1081659784841969665
- https://twitter.com/pedantcoder/status/904839926180569089
- https://twitter.com/pedantcoder/status/904840156330344449
- https://twitter.com/Catfish_Man/status/1081581652147490817
Don't use global queues
- https://twitter.com/pedantcoder/status/773903697474486273
- https://lists.swift.org/pipermail/swift-evolution/Week-of-Mon-20170828/039368.html
Avoid concurrent queues in almost all circumstances
- https://forums.swift.org/t/how-to-currently-offload-stateless-blocking-work-hidden-executor-api/59128/2
- https://forums.swift.org/t/how-to-currently-offload-stateless-blocking-work-hidden-executor-api/59128/12
- https://twitter.com/pedantcoder/status/960915209584914432
- https://twitter.com/pedantcoder/status/960916427833163776
Don't use async to protect shared state
- https://twitter.com/pedantcoder/status/820473404440489984
- https://twitter.com/pedantcoder/status/820473580819337219
- https://twitter.com/pedantcoder/status/820740434645221376
- https://twitter.com/pedantcoder/status/904467942208823296
- https://twitter.com/pedantcoder/status/904468363149099008
- https://twitter.com/pedantcoder/status/820473711606124544
- https://twitter.com/pedantcoder/status/820473923527589888
Don't use async for small tasks
- https://twitter.com/pedantcoder/status/1081657739451891713
- https://twitter.com/pedantcoder/status/1081642189048840192
- https://twitter.com/pedantcoder/status/1081642631732457472
- https://twitter.com/pedantcoder/status/1081648778975707136
Some classes/libraries should just be synchronous
Contention is a performance killer for concurrency
- https://twitter.com/pedantcoder/status/1081657739451891713
- https://twitter.com/pedantcoder/status/1081658172610293760
To avoid deadlocks, use locks to protect shared state
- https://twitter.com/pedantcoder/status/744269824079998977
- https://twitter.com/pedantcoder/status/744269947723866112
Don't use semaphores to wait for asynchronous work
- https://twitter.com/pedantcoder/status/1175062243806863360
- https://lists.swift.org/pipermail/swift-evolution/Week-of-Mon-20170828/039405.html
Synchronous IPC is not bad
The NSOperation API has some serious performance pitfalls
- https://twitter.com/pedantcoder/status/1082097847653154817
- https://twitter.com/pedantcoder/status/1082111968700289026
- https://twitter.com/Catfish_Man/status/1082097921632264192
- https://lists.swift.org/pipermail/swift-evolution/Week-of-Mon-20170828/039415.html
Locks are not as bad as people think they are (from libdispatch's original designer)
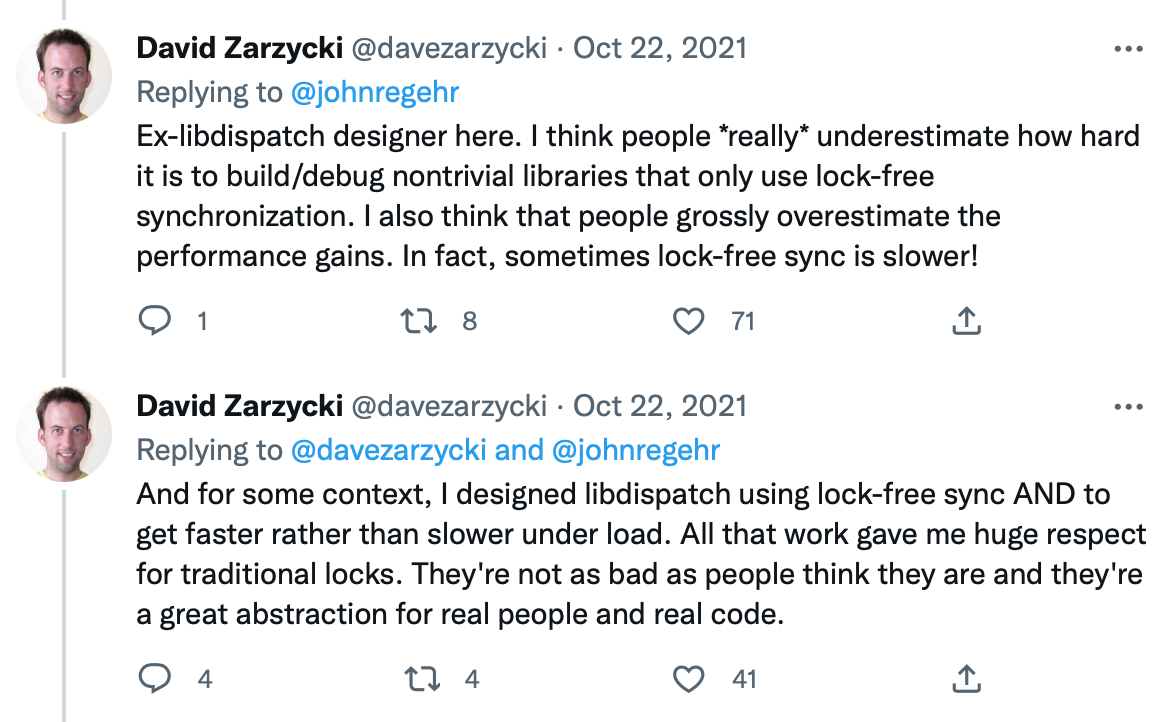{kind=link}
Avoid micro-benchmarking
- https://twitter.com/pedantcoder/status/1081660679054999552
- https://twitter.com/Catfish_Man/status/1081673457182490624
Resources are not infinite
- https://twitter.com/pedantcoder/status/1081661310771712001
- https://lists.swift.org/pipermail/swift-evolution/Week-of-Mon-20170828/039410.html
- https://lists.swift.org/pipermail/swift-evolution/Week-of-Mon-20170828/039429.html
Background QOS work is paused when low-power mode is enabled
About dispatch_async_and_wait()
Utilizing more than 3-4 cores isn't something that is easy
A lot of iOS 12 perf wins were from daemons going single-threaded
- https://twitter.com/Catfish_Man/status/1081673457182490624
- https://twitter.com/Catfish_Man/status/1081581652147490817
- https://twitter.com/Catfish_Man/status/1081590712376774661
- https://twitter.com/Catfish_Man/status/1374436077591695364
This page is the real deal
Very handy writeup, thank you!
A question, though: what is a "bottom queue"? Googling the term brings you back to this very gist.