Find the sample data here:
https://gist.github.com/reinink/30210fd48ef0435f475ed9d13270b09e
| select | |
| first_name, | |
| last_name | |
| from | |
| users | |
| left join | |
| companies on companies.id = users.company_id | |
| where ( | |
| companies.name like 'TERM%' or | |
| first_name like 'TERM%' or | |
| last_name like 'TERM%' | |
| ) |
Find the sample data here:
https://gist.github.com/reinink/30210fd48ef0435f475ed9d13270b09e
| Companies | |
| +------------+-----------------+------+-----+---------+----------------+ | |
| | Field | Type | Null | Key | Default | Extra | | |
| +------------+-----------------+------+-----+---------+----------------+ | |
| | id | bigint unsigned | NO | PRI | NULL | auto_increment | | |
| | name | varchar(255) | NO | MUL | NULL | | | |
| +------------+-----------------+------+-----+---------+----------------+ | |
| +-----------+------------+----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | |
| | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | | |
| +-----------+------------+----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | |
| | companies | 0 | PRIMARY | 1 | id | A | 10106 | NULL | NULL | | BTREE | | | YES | NULL | | |
| | companies | 1 | companies_name_index | 1 | name | A | 8624 | NULL | NULL | | BTREE | | | YES | NULL | | |
| +-----------+------------+----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | |
| Users | |
| +------------+-----------------+------+-----+---------+----------------+ | |
| | Field | Type | Null | Key | Default | Extra | | |
| +------------+-----------------+------+-----+---------+----------------+ | |
| | id | bigint unsigned | NO | PRI | NULL | auto_increment | | |
| | company_id | bigint unsigned | NO | MUL | NULL | | | |
| | first_name | varchar(255) | NO | MUL | NULL | | | |
| | last_name | varchar(255) | NO | MUL | NULL | | | |
| +------------+-----------------+------+-----+---------+----------------+ | |
| +-------+------------+--------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | |
| | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | | |
| +-------+------------+--------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | |
| | users | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | YES | NULL | | |
| | users | 1 | users_company_id_foreign | 1 | company_id | A | 0 | NULL | NULL | | BTREE | | | YES | NULL | | |
| | users | 1 | users_first_name_index | 1 | first_name | A | 0 | NULL | NULL | | BTREE | | | YES | NULL | | |
| | users | 1 | users_last_name_index | 1 | last_name | A | 0 | NULL | NULL | | BTREE | | | YES | NULL | | |
| +-------+------------+--------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ |
@reinink when you say convert to Eloquent, do you mean to end up with Eloquent models as a result, or to use the query builder type thing? If the former, I quite often use raw queries to fetch the IDs, then the orm to fetch the models. If the latter, that's a weird priority 🙂
@davedevelopment The first thing, exactly. I generally can convert most queries to the query builder, but it's sometimes hard to do with Eloquent if you're using a "computed" base table. Good idea on getting the IDs, and then doing a subsequent query. 👌
Which version of MySQL are you using? Are you using MySQL MySQL, or Maria, or some other fork?
What about these options:
return Cache::remeber('key-to-associate', 15, function() {
//here your localscope
});
like operator with a beginning match maybe could not be a good idea if when you run it this one makes a full table scanSELECT * FROM masters WHERE REGEXP_LIKE(degree, '^al');
I think this query gives you results that you expect with better performance, though it has a semantic difference. It doesn't do a table scan. I tested it with MySQL 5.7.29-0ubuntu0.18.04.1 on Ubuntu .
select
first_name,
last_name
From users
WHERE first_name like 'NAD%'
or last_name like 'NAD%'
OR company_id IN (select id from companies where name LIKE 'NAD%');
I think it's important to explain why this rewritten query works better.
The original query first does a join between the users and companies tables. Of the matching tuples, it finds the rows that match the LIKE conditions in the WHERE clause. The QP must do the join first to generate candidate rows for the WHERE clause. The execution plan of the original query enumerates all the rows in the companies table. For each row enumerated, it probes the Users table to find a match on company_id. If found, it further filters to see if the LIKE clauses match.
It seems like the goal (the complaint?) is that the filters aren't applied to tables on both sides of the join first, we'd only have companies that match the WHERE clause, and couldn't JOIN users that matched their clauses in the WHERE. All of the LIKE clauses are disjunctive -- they're OR statements. If we filtered a row from the Users table, we'd still maybe want to match it because OR Companies.Name LIKE was a match.
The query I wrote has a semantic difference; it will return rows from users that don't have a matching company. I think the OUTER JOIN was meant to take care of that, but I'm not positive it will. (Because NULL is NOT LIKE anything, so ... but I'm not positive of that, and I have too much lockdown time to think particularly clearly.)
My revised query will poke at the first_name index, then the last_name index, both on the users table. Then, with a subselect, it develops a list of company_ids that match using the names index on the companies table; it will probe each resulting entry in the company_ids index on the users table. All the results are then projected back to the user.
We all want SQL statements to run as fast as possible, but getting good performance has to start with careful thought about what the statement we're executing really does, and how it really works.
@mikeblas Thanks for sharing your thoughts. You'll notice that I did try this query, but it's still giving me 10ms+ (or worse) performance, where running two queries got me <1ms per query.
So, just an update here, for anyone who is interested. 😂
I managed to get this query working in Laravel, as a SINGLE query, using the union approach, where it supports searching multiple queries. 🎊
The following is my final User model scope.
Brace yourselves. 😬
public function scopeSearch($query, string $term = null)
{
collect(str_getcsv($term, ' ', '"'))->filter()->each(function ($term) use ($query) {
$term = $term.'%';
$query->whereIn('id', function ($query) use ($term) {
$query->select('id')
->from(function ($query) use ($term) {
$query->select('users.id')
->from('users')
->where('users.first_name', 'like', $term)
->orWhere('users.last_name', 'like', $term)
->union(
$query->newQuery()
->select('users.id')
->from('users')
->join('companies', 'users.company_id', '=', 'companies.id')
->where('companies.name', 'like', $term)
);
}, 'matches');
});
});
}And the generated query (for the search "bill gates microsoft"):
SELECT
*
FROM
`users`
WHERE
`id` in(
SELECT
`id` FROM ((
SELECT
`users`.`id` FROM `users`
WHERE
`users`.`first_name` LIKE 'bill%'
OR `users`.`last_name` LIKE 'bill%')
UNION (
SELECT
`users`.`id` FROM `users`
INNER JOIN `companies` ON `users`.`company_id` = `companies`.`id`
WHERE
`companies`.`name` LIKE 'bill%')) AS `matches`)
AND `id` in(
SELECT
`id` FROM ((
SELECT
`users`.`id` FROM `users`
WHERE
`users`.`first_name` LIKE 'gates%'
OR `users`.`last_name` LIKE 'gates%')
UNION (
SELECT
`users`.`id` FROM `users`
INNER JOIN `companies` ON `users`.`company_id` = `companies`.`id`
WHERE
`companies`.`name` LIKE 'gates%')) AS `matches`)
AND `id` in(
SELECT
`id` FROM ((
SELECT
`users`.`id` FROM `users`
WHERE
`users`.`first_name` LIKE 'microsoft%'
OR `users`.`last_name` LIKE 'microsoft%')
UNION (
SELECT
`users`.`id` FROM `users`
INNER JOIN `companies` ON `users`.`company_id` = `companies`.`id`
WHERE
`companies`.`name` LIKE 'microsoft%')) AS `matches`)
ORDER BY
`last_name` ASC, `first_name` ASC
LIMIT 15 OFFSET 0Overall, the final results are amazing.
Running it for three terms (ie. "bill gates microsoft"), against 1 million users, and 100,000 companies results in query times between 3-6ms.
The trick? Err..tricks?
First, using a union (as folks have suggested) allows the query builder to run each query (the users match and companies match) independently of each other, and therefore use all the available indexes. This final query now successfully uses the users_first_name_index, users_last_name_index and companies_name_index.
Second, and this was the piece I was missing before, you must run this union as a derived table, not a normal (correlated/dependent) subquery.
Without the derived table, all of subqueries are "dependent":
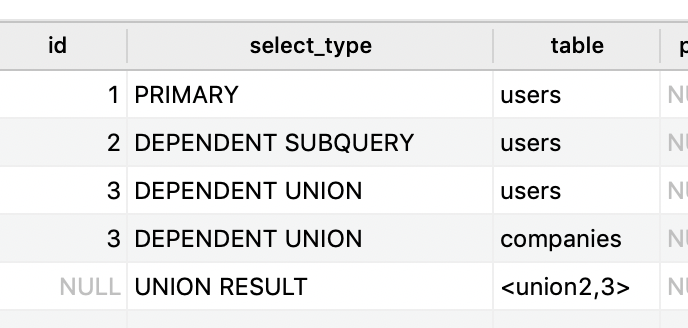
Adding the derived table makes all the problems go away:

I would have thought that the sub queries would only be dependent if you actually had some type of dependency between the two. For example, inner.id = outer.id, or something like that. But I guess the MySQL query planner doesn't look at the conditions to see if these two queries are actually dependent.
The only outstanding issue I have still is running a 1-2 character search. For example, searching for "b", or even "bi" is rather slow, taking upwards of 800ms on a million rows. The previous approaches that don't use the indexes are faster in those cases. I suspect that this is because the derived tables end up becoming massive, and that just takes computation time. One simple solution is to just not perform the search until you have at least 3 characters, which seems to be the sweet spot.
And, now for a quick sales pitch. 😂
I plan to cover all this in detail in my upcoming Eloquent Performance Patterns course. If that sounds interesting to you, be sure to join my mailing list on that website. 🤟
@reinink - interested in the course - the above is very close to an issue I want to solve - so wondering if the course will cover it - querying unrelated data at the same time and returning not just the ID of the model, but the table reference it is derived from, in the return?
The purpose is to allow users to just have one search box to find any one model in the search. So say you have 4 tables - COMPANY, SERVICE, PRODUCT, and DEVICE. I want to design a query that queries for a typeahead "meta" search of the description or name (or some other column) in each table, and returns the ID and the model type (i.e. table reference) so that if someone selected that, it would take them to that particular record. Right now these are 4 different searches on my application - in other words, the person needs to know they are looking for a DEVICE, and then search the DEVICE table.
I think this can be done with Unions - just including an AS column (from an SO post):
(SELECT content, title, 'msg' as type FROM messages WHERE content LIKE '%" .
$keyword . "%' OR title LIKE '%" . $keyword ."%')
UNION
(SELECT content, title, 'topic' as type FROM topics WHERE content LIKE '%" .
$keyword . "%' OR title LIKE '%" . $keyword ."%')
UNION
(SELECT content, title, 'comment' as type FROM comments WHERE content LIKE '%" .
$keyword . "%' OR title LIKE '%" . $keyword ."%')";In my case the tables have different columns in each table, so instead of say content, title above, say the table has description, name in one of the tables. As per your post above, however, I suspect this is not performant at all . . . and thus have not implemented it.
In any event, I am on your email list and very interested in this course and really appreciate the above gist and all the comments on it.
So, thanks to everyone for helping with this problem. It blows my mind how hard this has been.
As many of you suggested, the UNION approach is very fast. The problem, however, with the UNION approach is:
I almost thought that @Cacobot had the solution, but after some testing, it has some really weird side affects where every SELECT column and ORDER BY added REALLY slowed it down.
As of right now, the best possible solution I can come up with is running a separate query to get the companies for each term, before running the main query. Here is what this looks like in Laravel:
It seems insane to introduce an N+1 intentionally, but I don't really have a better solution, and the results are actually really quite good. Here are the queries that are generated:
In and around
5mstotal, between all the queries. That's really fast. Much faster than any single query solution I could come up with.The only thing that's a bummer is Postgres. This solution doesn't work quite as well there, although it's still better than most options. I'mg getting around
90mstotal between all the queries with this approach in Postgres.One last note, these numbers are not based on the original 30,000 users, 10,000 companies. I bumped that up to 200,000 users, and 50,000 companies.