- welcome everyone!
- we have a code of conduct
- thanks to organisers, sponsors, etc
- Dan Young, EngineerBetter (@dan0young)
- we come from very different backgrouds
- I run a small software consultancy
- Emma Hogbin Westby, United Nations, OCHA (@emmajanehw)
- (I don’t speak on behalf of the UN!)
- we’re a completely distributed team
- this talk
- who we are
- what is a humane team?
- how can we improve?
- actionable content
- dan mostly collocated, emma mostly distributed
- Dan: XP, pair programming, pivotal way
- we always favour collocated teams
- Dan: XP, pair programming, pivotal way
- audience: how many people are on:
- pure collocated? (about 1/3)
- pure distributued (perhaps never met some coworkers?) (about 10-20)
- mixed?
- gitlab has written up some notes on how to build a pure-distributed organization from scratch. there’s about 160 people, all in separate locations. They’ve written up some things on how they cope
- The spiral is:
- Low Trust/Low Safety
- No authentic communication, issues not surfaced.
- Wasted time and effort; lack of accountability
- Poor sense of progress. Folks checked out
- GOTO 10
- you can address humane working with different styles of teams
- Dan: in my business, we started with a strong focus on
collocation, but eventually it became impossible
- we broke the team :(
- we moved from a collocated context to a distributed context with no prep
- no video conferencing
- no support for remote pairing
- no way to support new hires
- Emma: we were having weekly meetings. When Dan says we didn’t
have the schedule worked out
- eg standup not starting on time
- what can you do to fix that?
- they need to just turn up!
- but they’re not going to unless you put structure in place
- well, the equipment doesn’t work
- maybe that’s something you can fix
- “Humane” is subjective
- Emma: i really dislike the idea of pairing, i find it pretty “inhumane”
- “humane” = productive and effective; “inhumane” = unproductive and ineffective
- “Heroes”
- hero culture: is it humane?
- lots of negative connotations
- but: when you are the hero, you feel really good about the work you are doing
- it results in:
- burnout
- tasks not completed
- hero culture: is it humane?
- Dan: I’ve also had people complain about pairing but conversely,
when you’ve experienced it you can also see how fun and
rewarding it can be
- i’ve also done mobbing (extreme pairing!)
- no meetings
- no standups
- nightmare for management
- i’ve also done mobbing (extreme pairing!)
- Emma: but: if you have a distributed team with only one person in Australia, that person needs to be able to go into hero mode when the outage happens in their timezone
- look at how team members go through a team:
- joining - onboarding
- while(isMember?) - working
- plan
- execute
- review
- leaving - offboarding
- Emma: as a distributed team, we have a great written culture
- documentation
- checklists
- issues/bugs
- this is great for onboarding
- we have a number of things we pull out of the publicly available GDS welcome package
- we had our first Windows developer join recently
- we use docker
- no docs for how to get things working
- we needed to have a process where we helped the new joiner and updated the documentation as we went
- we have offboarding for free
- then the working cycle:
- planning
- sprints / iterations / whatever planning methodologies
- I really miss whiteboards and post-its
- collocated teams really have the advantage here
- there’s something unique and special about collectively filling a wall with post its
- there’s no real equivalent with a distributed team
- review:
- retrospectives with a distributed team
- people are more likely to shy away
- let someone dominate conversation
- check email
- check out
- there are strategies for this
- ask explicit questions ahead of time
- get people to come prepared
- it’s still hard compared to collocation, where you can read body language
- execution
- I really like to give people large blocks of solo time to
get on with their work
- don’t ping someone on text chat unless you really want to disrupt their workflow
- this is not the experience of pairing
- Dan: we don’t have any rules about interrupting
- do it in a socially sensitive way
- I really like to give people large blocks of solo time to
get on with their work
- planning
- prepare for the schedule you are planning to work
- have the right technology
- make work achievable
- make stories as small as possible
- endorphins!
- (what about architecture/high level design?)
- make stories as small as possible
- if it works, write it down
- don’t be afraid to change what you’ve written
- Emma: “passive-aggressive documentation”
- i had a colleague who preferred merge - I preferred rebase
- the documentation went back and forth between preferring one or the other
- but this process allowed us to have this conversation about what we were actually trying to achieve
- work from shared values
- xp values
- instead of death spiral:
- Respect
- Courage
- Communication
- Feedback
- instead of death spiral:
- agile manifesto
- start with shared values
- make work achievable
- prepare for your next context
- codify what works
- resources: https://github.com/humane-teams
- Igor Galić @hirojin
- I moved from operations to development and I’m here to tell you my story
- I’m queer
- My first language was serbo-croatian
- other languages include C
- I am a classically-trained unix systems administrator
- C, C++, Java, IBM 360 assembler, PL/I
- this is pretty much the reason I stopped programming
- How to build a distro
- How the Unix Runtime works
- How to build Software
- How to debug the runtime, aka strace(1)
- how to install software
- the most important tool in ops is saying “no” to everyone
- reading code of literally any language
- I’ve supported a lot of Java apps
- I’ve never written Java myself, but I’ve read a lot of Java stacktraces
- Automation is important
- perl, bash, ruby
- make (I’m friggin serious)
- idempotency
- systems and more systems
- I learned from Rich Bowen how to be patient when supporting people
- Design & Architecture
- Building & Debugging “distributed” “systems”
- On call
- surviving on minimal sleep
- followed by maximum alcohol
- https://twitter.com/dberkholz/status/902164887496949760
- “I really like that Puppet’s talking about code and development, not scripting (often a pejorative).”
- culture-unfit
- the team i was working on hired a new full time person
- he had a working style which noone could work with
- i moved to a different team
- developing an infrastructure provisioning tool in golang
- i had to accept this
- “maintaining a million puppet modules has taught me one thing: not a single piece of software was written with automation in mind.”
- Ops tools in dev
- known good config format
- well behaved (idempotent) configuration tool
- packages
- atomicity
- version numbers that can be “trusted”
- discoverable
- don’t accidentally make your own package manager
- services
- use your init system!
- log rotation!
- run batch jobs with a scheduler!
- “Any sufficiently complicated Go program contains an ad-hoc, informally-specified, bug-ridden, slow implementation of half of Lua.”
- Start advocating for everything you’ve always felt was missing!
- UI/UX in CLI tools
- documenting bad code vs refactoring
- support - like admin of the day
- known good config format
- what to leave behind
- there are no new ideas
- ops people are afraid and say no because new things break
- eg: Rust
- all the ideas in Rust are 20-50 years old
- fear of inadequacy
- i’m not an imposter
- i’m just not a very good programmer
- missing dev tools
- FreeBSD manual of programming?
- every part of administering a freebsd box
- Linux from Scratch manual of Programming?
- empty VM to functioning linux distro
- relentless repetition
- books
- eloquent javascript 2e
- how to design programs 2e
- javascript for kids
- ruby wizardry
- shell
- sometimes you have to bite the bullet and learn a new thing
- sometimes you can use what you already know
- pry!
- you can
cdandlsthrough ruby code - since I discovered pry, i wanted every programming system to have it
- you can
- python: jupyter
- clojure: clojure itself!
- erlang & elixir: iex
- ruby under a microscope
- ERLANG IN ANGER
- $$$$$$
- ops folks usually make less money than devs
- if you become a dev, you might want to renegotiate your salary
- FreeBSD manual of programming?
- That’s all folks
- Sally Goble @sallygoble
- Head of Quality at the Guardian
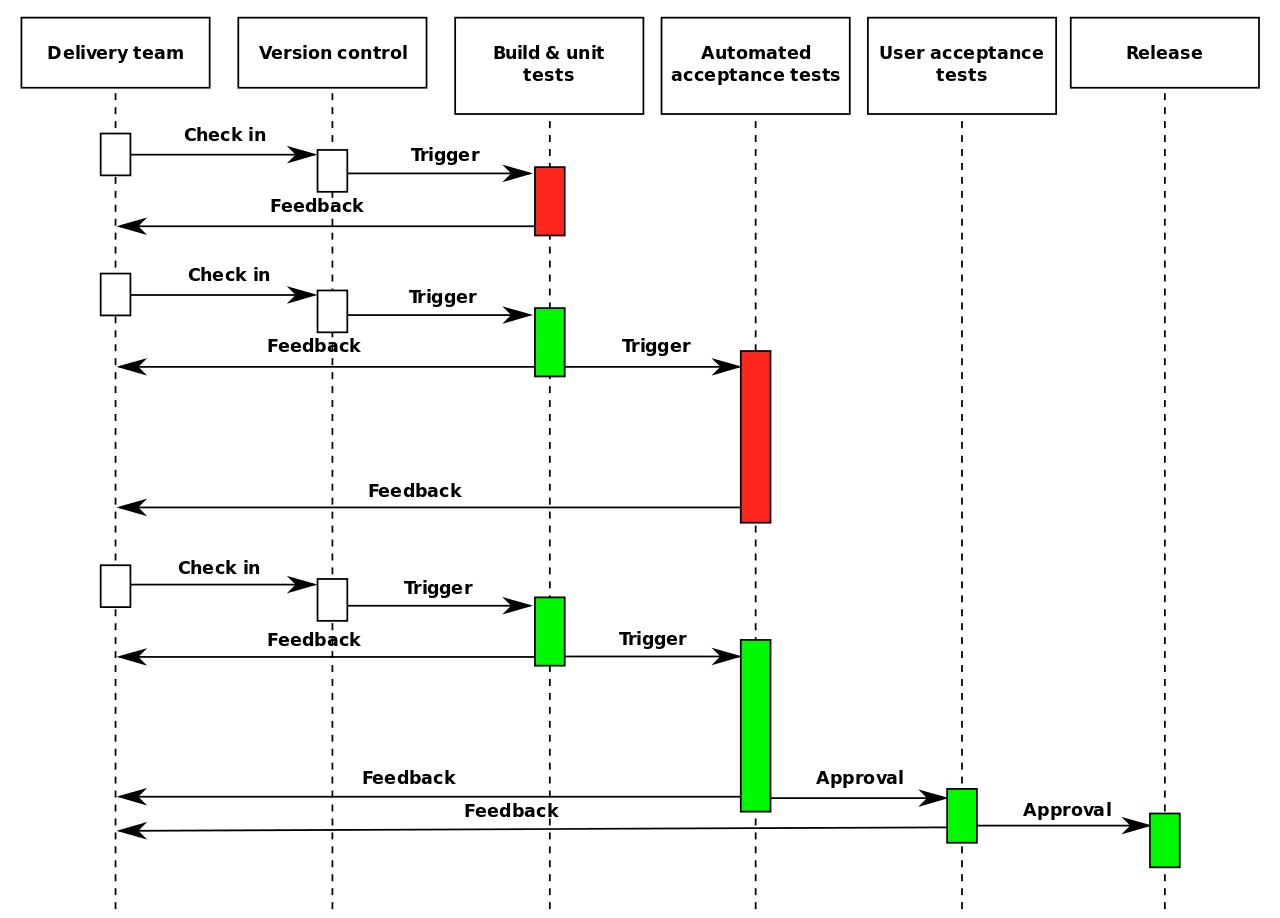
- we release our software >100 times a day
- the nature of CD means we should fundamentally rething testing and QA
- old days of software delivery:
- shrinkwrapped boxes
- install disks
- bricks-and-mortar shop
- physical money
- upgrades
- wait a year or two
- go back to shop
- software had to be “perfect” as a consequence
- fully feature
- anticipate user’s needs for a year
- anticipate the market
- bug free
- if there were any problems, you had to wait a year and a half to fix them
- the rhythm of delivery was non-negotiable
- but: then the internet happened
- could accelerate the speed at which we deliver software
- how did that change the role of QA/testing?
- 2010: “fast-ish” delivery at the guardian
- I was responsible for testing our monolithic frontend
- we released that software in a cycle every two weeks
- the release process had all the things you expect
- release managers
- code freezes
- go/no go meetings
- regression suite
- took 2 people 2 days of intensive manual testing to ensure everything we shipped to production was “perfect”
- we were locked in to 2 week release cycle because of some bad
decisions about architecture
- couldn’t deploy without downtime
- 5am deploy window
- long, cumbersome deploy process
- required specialists
- took half an hour
- we needed to speed this up
- engineering made a bunch of architectural changes to fix this
- in-house tool to deploy at-will to any env at any time
- brilliant for engineers
- but: QA team thought - argh!
- QAs: “we needed to speed up”
- automated tests! that’s the holy grail
- we sat in a room for a year and wrote tests
- we were ready to go
- but!
- the tests were flaky, unreliable, slow
- everyone hated them
- our eureka moment!
- our obsession with testing everything carefully before we
released it was fixing a problem we no longer had
- we could fix problems when we noticed them, rather than needing to wait for next release window
- threw away automated testing and manual prodding
- bare minimum of testing to ship something
- didn’t need to be a QA doing the testing
- adopt the attitude of “not long wrong”
- ship it, and if it breaks, fix it then
- people’s response: “are you mad? that sounds very risky”
- if you’re writing software for a car, or a nuclear power station, don’t do this
- toolbox of techniques:
- single feature releases
- aggressive caching
- feature switches
- canary releases
- monitoring and alerting
- post release techniques
- beta programmes
- 12 of us
- testing ≠ quality
- ironic that we were the “QA team” when all we did was testing
- we live up to our name better now
- help teams to improve their own quality
- expose metrics to all - transparency
- eg: people asked us to test ads before they went live
- we said no: we’ll help you test them for yourselves
- performance tooling
- eg: liveblogs became quite heavy and started crashing
- tool to automatically poll and measure these pages
- alert if they go over a threshold
- alert goes to journalist
- telling them which embeds are too large
- and advising on remedial action
- change size of image or encoding of video
- alert goes to journalist
- eg: people asked us to test ads before they went live
- find problems in production quickly
- previously: test before production, then forget
- tools to help us find production bugs
- eg: critical but (relatively) infrequent user journey: pay for
somethin
- run a selenium test for this journey on each deploy
- alerts via github PR if test fails
- we now look for transactions from real users and note when
the first one comes through and alert
- QUESTION: should the alert be for an absence of txn?
- synthetic monitoring
- webdriver testing
- editorial tools - creates an article then takes it down
- this alerts us before our journalists do
- webdriver testing
- operational metrics
- testing for mobile apps
- it’s not always obvious when you’ve broken a particular mobile device
- want to improve confidence that we see things quickly
- anomaly detection
- use existing business analytics to see how many users from each device are expected to use a particular feature
- if the number drops precipitously, alert
- crowdsource our users
- beta programmes for apps
- apple restricted our release process
- you can only release your app as frequently as apple will review your app
- we have thousands of users in our android & ios beta programmes
- we release betas several times for each production release
- requires a large and loyal user base
- QA is no longer a barrier
- users & stakeholders are happy - faster delivery of features
- QA are happier & more satisfied
- Alvaro Videla - @old_sound
- I live in Switzerland right now - before I lived in China, before Norway
- This talk also appears as an ACM Queue article
- 1980, book: metaphors we live by
- metaphor isn’t just a matter of poetry and rhetorical flourish
- metaphors dicate
- how we think
- how we behave
- argument is war
- this is a metaphor
- “your claims are indefensible”
- “he attacked every weak point in my argument”
- “i never won an argument with him”
- “his criticisms were right on target”
- what if argument were a dance?
- not convinced? let’s talk about politics
- how metaphors shape women’s lives
- experiment to show how metaphors of crime can affect people’s
decision-making
- “wild beast” metaphor vs “virus” metaphor
- “beast” recipients more strongly favoured crime-and-punishment response
- still not convinced? let’s talk about human resource management
- when you think of humans as “resources” you think they are fungible
- people ≠ resources
- (trigger warning)
- there is a conference which likes to invite nazis to give keynote speeches
- organizer’s defence: “wrestling with inclusion at xyzconf”
- wrestling?
- “computers” were originally people who performed calculations
- our industry is founded on a metaphor
- metaphors enable understanding
- “Juliet is like the sun”
- this tells us a lot: she makes me feel warm, she gives me life
- we also manage to avoid conclusions like “Juliet gave me skin cancer”
- metaphors transfer information from one conceptual domain to
another
- what is transferred is a pattern rather than domain-specific information
- this is how metaphors create new knowledge
- they can also obscure understanding
- tele-graph
- (why is the Daily Telegraph called the telegraph? probably because it was a buzzword at the time it was founded)
- tele-graph
- “Sometimes our tools do what we tell them to. Other times, we
adapt ourselves to our tools’ requirements” – Nicholas Carr
- this happens with metaphors too!
- what a programmer does
- to program is to write to another programmer about our solution to a problem
- “programs must be written for people to read, and only incidentally for machines to execute” – from SICP
- programming with abstract data types by Barbara Liskov
- why does all this matter?
- choosing the right data structure amplifies the meaning of your
program
- arrays vs sets vs linked lists vs queues vs stacks
- choosing the right data structure amplifies the meaning of your
program
- task scheduling
- when we understand that this problem is one of managing a queue, we have the whole of queueing theory that we can apply
- route planning
- graph theory
- Borges says: you can’t have a map which captures every single detail of a city, because then what’s the point of it?
- database replication
- rumour mongering
- fan-out tree of communication
- but: problems applying the metaphor
- a more apt metaphor: epidemics
- information spreads around
- comes with a mathematical theory of spreading
- rumour mongering
- still don’t believe me? here’s a list of distsys metaphors:
- peers
- leader
- consensus
- election
- bottleneck
- message
- channel
- dead
- respond / response / unresponsive
- another metaphor: containers
- they brought a whole bunch of metaphors which make it easy to
understand the idea
- standard
- ship anywhere
- train, ships, trucks
- stackable
- reusable
- I think this metaphor is one of the reasons the idea spread so far
- JVM and Erlang had similar things before but didn’t catch on nearly so much
- they brought a whole bunch of metaphors which make it easy to
understand the idea
- microservices!
- erlang can do this already?
- “monolith” is a great metaphor
- especially for winning arguments :)
- what is erlang’s elevator pitch?
- also: rabbitmq
- I was a rabbitmq core developer
- people asked if it was a “job server”
- I said “no, it’s a message server”
- emphasizing that it’s much more general
- but: people understand jobs
- it’s a good starting point for understanding
- master the art of metaphor selection
- then explain how things actually work
- our program is the metaphor for the solution we found
- project: retailer with long release pipeline
- releases years apart rather than weeks
- environments took over 4 weeks to set up
- wanted to get down to 4 hours
- we had tools in place
- but they hindered rather than helped
- ADOP - had tools set up
- process
- take apps, one by one, break them down, go through manuals, find depedencies
- used terraform to deploy in azure or oracle public cloud
- ansible playbooks to automate configuration
- containerized all our tools to be able to use them on whatever
platform
- reliability and resilience for free
- don’t underestimate the complexity of automating COTS
- KISS - don’t overengineer
- search engines are your best friends
- your colleagues come next :)
- don’t trust output codes
- always check the logs for “error” or “fatal”
- reduced from a month and a half to a full working day
- testing is still seen as a barrier to CD but that shouldn’t be the case
- what is crowdsourced testing?
- use real users/testers, testing in real world conditions
- how we started
- 3 scrum devs
- only 1 tester
- tester was swamped
- crowd test cycle process
- prepare -> run -> analyze results
- challenges
- devs rejecting lots of bugs
- distrusting crowd testing
- approach
- decide where to start
- adjust strategy
- stick to timeboxes
- track improvements
- a good preparation is the key
- input
- test scope
- testers need to know this to avoid wasting time
- known issues
- release notes
- test scope
- whole team approach
- input
- how to succeed
- foster communication with crowdsourced testers
- star and reward the good testers
- further tips
- exploratory tests add lots of value
- more so than regression
- higher motivation
- CT won’t solve all your testing, QA or dev problems
- test internally as well
- I’m kate (@GOK8) and I love math!
- I’ve seen lots of people with math skills elevated to management, but who have no people skills
- old days: women who got pregnant while working were expected not to return
- chaos theory is coming!
- dance between turbulence and order
- the thing in today’s workplace that’s present is the human factor
- millenials are making sweet, sweet chaos in the workplace
- the employee of today expects to be heard and considered in decision making
- doesn’t want there to be a lack of diversity in senior management
- voice of leadership is the small change that can trigger huge (and unpredictable) changes in the organization
- chaos should not freak you out
- embrace your feedback loops
- embrace the polymorphism in your team and policymaking
- @ttarczynski
- when i started my first monitoring system looked like this: <picture of angry customer>
- wrong moment for failure: when I’m on holiday
- to improve this, I put a monitoring box in place
- status probes to detect failures
- monitoring gives comfort
- I could be notified of failures quicker and react faster
- reduced my stress
- over the years, the systems evolved
- complex systems
- devops -> automation
- moving faster
- developers could easily deploy new code
- but: more failures
- monitoring done for ops only
- only one expert on team who knew it well
- #monitoringsucks
- no time to improve
- constant firefighting
-
- how many code changes we push per day/week/month
- what data do we collect - is it working?
- when we use it for alarming - do we have the right strategy for that?
- what is the purpose of collecting metrics? what are you trying to achieve?
- “if there’s a number, save it - it might be useful in future”
- metrics:
- £ per day
- iteration time
- shopping cart abandons
- as close to the business outcomes as possible
- it feels like we’re using the word “metrics” to describe several
things
- data v information v knowledge
- django code of conduct reporting guide
- the no asshole rule
- Meri Williams - conference talks and people management training
- didn’t catch the specific conference talk name sorry :(
- this was a re-run of this session by pat debois at devopsdays paris 2013
- Erik Sasha Romijn
- Sasha for short
- @erikpub
- i used to see a lot of people at conferences who seemed to get
on well with everyone, who seemed to have it all together
- i was surprised to learn eventually that some of them have had serious problems with depression, loneliness, etc
- about 1 in 4 people will experience metnal illness in their
lifetime (involving formal diagnosis and treatment)
- there are other people in this room with similar struggles
- djangocon europe 2015: 1 in 10 attendees spoke to a counselor
(which was provided for free)
- counselling isn’t an immediate fix to all your problems
- but it can provide benefits by merely acknowledging your problems are real problems
- we’re not mental health professionals
- but we can make a difference
- when being helpful may not help you
- this is when things can get dangerous
- putting yourself first isn’t always selfish
- metaphor: put your own oxygen mask on before helping others
- helping yourself first literally saves lives
- it’s ok to say “no”
- and it’s even ok to say “no more”
- we’re afraid that if we step down then people will look at us in a negative way
- my collaborator on this talk had gone through a lot of things:
- career change
- local to remote work
- lots of side projects
- not enough time to work on this talk!
- we had a serious conversation about sustainability
- thankfully, she agreed to cut some things down, and focus on this talk
- what you do ≠ who you are
- saying no to things doesn’t diminish you
- there can be a culture of overachivement/overcommitment
- being a volunteer (eg in an OSS community) means that nobody has to contribute
- fear of the unknown
- it can be scary to say “no” or “no more” because you don’t know how people will react
- but ultimately this fear is often more destructive than the reaction turns out to be
- further, staying in a role that I don’t have capacity for is
like licking the cookie but not eating it
- nobody else can do it while i’m in the position, but i’m not doing it satisfactorily
- things that push us to overcommitment
- github commit graph
- especially: number of days streak
- don’t take any days break ever
- i made top of newsy for this
- i was described as “leftist tyranny” and “neoliberal emotional crusader”
- especially: number of days streak
- github commit graph
- at djangocon, we have put volunteers in place who can be asked
about anything at any time
- people really liked it!
- this talk started because I asked for help getting together some
half-baked ideas
- this talk would not exist if i hadn’t asked for help!
- asking for help is not the same as failing
- if i tried to organise a conference on my own, it would literally kill me
- it can feel like asking for help is admitting that you have a
problem
- you might try to comfort yourself by ignoring the problem (head in the sand)
- but: asking for help doesn’t create the problem, it merely acknowledges it for what it is and starts the process towards fixing it
- others don’t know what you need if you don’t ask
- “I know that vulnerability is kind of the core of shame and fear and our struggle for worthiness, but it appears that it’s also the birthplace of joy, of creativity, of belonging, of love. And I think I have a problem, and I need some help.” – Brené Brown, from TED Talk: The Power of Vulnerability
- asking for help is part of being part of a community
- i work for django conferences
- it’s a lot of work!
- but it’s short-term stress and i can cope with it
- we don’t feel we need to tell people we appreciate them
- but this feeling of being appreciated matters and is important
- send people happinesspackets!
- twitter bot: yayfrens
- please be kind to each other, but also to yourselves
- Louise Paling @short_louise
- From Alistair Cockburn:
- “I’m tired of people from one school of thought dissing ideas from some other school of thought. I hunger for people who don’t care where the ideas come from, just what they mean and what they produce. So I came up with this “Oath of Non-Allegiance”.”
- http://alistair.cockburn.us/oath+of+non-allegiance
- lots of us come from successful waterfall projects
- team board / kanban board
- standups (from scrum)
- getting rid of dev/ops/QA silos
- no separate requirements teams like in the old days
- scaled agile
- SAFe, less, dad, nexus, etc
- SAFe - I hated it on sight, it looks bad
- but i looked in detail and there’s some good ideas in there
- idea: across multiple teams, have a combined planning session
- dependency boards to get an idea of roughly at what times
particular dependencies will happen
- still agile - can still change
- continuous delivery
- let’s always go faster
- continuous is faster than you think
- automation is key
- the part i really like is this diagram of the CD pipeline
- the idea of the single chain through to production is really important
- it helps focus the mind
- waterfall
- risk management
- this is common sense, not purely waterfall
- risk management
- theory of constraints
- who’s read the phoenix project (it’s a rewrite of the goal by goldratt, now published as graphic novel)
- user story mapping / process mapping
- ITIL
- Change management is important
- not as box ticking or authority assertion
- appropriate change management
- Change management is important
- lean startup
- build/measure/learn cycle
- “MVP” comes from here
- the smallest amount of work that allows you to get round the loop one more time
- XP
- pair programming
- cynefin
- from the welsh
- know what state you’re in so you can take appropriate action
- chaotic - incident response
- checklist manifesto (from Atul Gawande)
- Atul Gawande is a doctor, uses checklists to save lives
- pilots on takeoff
- surgeons
- these aren’t stupid people!
- helps to make sure they’re on track and they know what they’re doing
- two kinds:
- you already know what you’re doing, but if you’re not
careful you get complacent and forget a step
- pilots taking off
- people don’t do the same thing every time, or very
frequently, but when the event does come up, you need to
checkilst to say how to deal with it
- incident response manual
- you already know what you’re doing, but if you’re not
careful you get complacent and forget a step
- pomodoro technique
- it’s really hard!
- note down any interruptions
- you’ll find so many of these that you didn’t know you had
- multitasking is bad - let people concentrate
- monte carlo estimation
- estimates aren’t facts
- we all know this in theory
- with monte carlo, you come up with three estimates:
- best case
- most likely
- worst case
- rather than adding them up, you run it through a simulation
- do 10,000 runs
- get a spread of possibilities
- there are other kinds of estimation than planning poker!
- estimates aren’t facts
- people are the root of all problems
- everyone should change, except me, my stuff’s great
- people are also the cure for all our problems
- one size doesn’t fit in all situations
{kind=link}
- Aubrey Stearn
- PizzaHut Digital Ventures
- @auberryberry
- “If it doesn’t work in a phone box, it’ll never work in a pub fight”
- it’s a shift from monolithic and bloated tooling to leaner things
- it’s more human-centred interfaces
- can use it with anything
- hipchat, slack, etc
- real time execution of tooling with collaboration and transparency
- I’m no longer alone, I’m usually surrounded by my team
- “I can’t get a macbook into a handbag”
- screenshot: me, in real time, in slack, taking a pizza hut branch off the website, from my phone
- knowledge is inherently perpetuated
- people who might never have directly executed these commands for themselves suddenly see how things are done
- process
- poll something for errors!
- you could use webhooks
- polling can (surprisingly) be faster
- push errors into pipeline one by one
- apply procesors to errors
- output with bot
- poll something for errors!
- pipeline: triage / actions / stats
- common pitfalls
- ZOMG let’s integrate everything ever!
- circle / git / all the stuff on the wall
- just ends up with noise
- no value whatsoever
- syntax chaos (ie “how do i enter this command?”)
- barrier to adoption
- ZOMG let’s integrate everything ever!
- i made a monolith :(
- the pinnacle of chatops?
- you’ve made a monster
- it’s part of your production environment
- you can’t lose it
- it’s a liability
- how do you break this up and reduce/manage risk?
- how do you still execute commands you’ve come to rely on if the bot goes down?
- or if slack goes down?
- argh!
- interesting challenges to scaling out chatbots
- can’t simply horizontally scale or you get duplicate responses in chat
- scale-api
- like mechanical turk
- use it for managing incoming emails from pizza hut managers
- transform natural language into hutbot commands
- although: “immediate” in scale-api terms is “within 6 hours”
- so.. it didn’t work out like we wanted
- replaying issues
- canary
- tell us if something goes wrong as soon as possible
- anomaly detection
- you need
- chat client
- hipchat
- messenger
- slack
- cisco spark
- skype
- flowdock
- need to consider:
- security
- new attack vectors - if someone grabs your phone and starts executing random chat commands
- context
- security
- bot
- hubot from github
- lita
- botkit (nodejs)
- script
- chat client
- Jon Topper - @jtopper
- there’s always something new to be going and looking at
- machine learning / blockchain / schedulers / containers / etc
- a lot of us got into the industry as hobbyists
- excitement is a good thing
- things that are boring are powerful from an operational perspective
- eg: if you’re on call you want it to be boring, not exciting
- huge choice of things when starting a new project
- languages, environments
- got to be careful with fashion
- eg mongodb
- not to hate on it
- it rose to popularity amazingly quickly after being founded in 2009
- it took 2 years to get data journalling (for write safety)
- another major release after that to get authentication
- another couple of years for role-based access control and TLS
- another year for audit logging (enterprise only)
- november 2016 was first version to pass jepsen test suite
- we should make decisions based on business considerations
- if your business cares about possibility of losing data, mongodb in 2012 probably wasn’t a good choice
- fashionableness decreases over time
- reliability increases over time
- security increases over time
- collective knowledge increases over time
- stack overflow answers are easier to read than gdb output
- software becomes boring over time
- hacker news driven development D:
- development considerations vs operational considerations
- vs user considerations
- users don’t care what your
- only innovate to differentiate
- spend your innovation tokens wisely
- summary
- fashionable software carries risk
- I’ve been doing this for 1.5 years now, it’s been a journey
- I started devopsdays along with patrick debois in ghent
- I run a bunch of conferences - cfgmgmtcamp (after FOSDEM in ghent)
- jenkins as example
- OSS tool
- widely adopted
- UI focused - causes pain
- I have lots of pipelines
- teams running projects with similar software
- php, python/django
- creating a new project:
- jenkins “copy from”
- dirty clickers
- scaling pipelines
- create a pipeline
- for job in pipeline
- create job from old job
- generating pipelines
- template the xml files
- put it in puppet
- didn’t work
- PipelineDSL
- Jenkinsfile
- really nice if you go straight
- buggy
- Jeknins Job DSL
- in groovy
- flexible
- well supported
- for every type of project we have a template
- source in git
- rebuild every job every time source template changes
- jobs are now code
- track the changes in the pipelines
- standardization
- similar feedback
- same emails on failure
- other tools:
- travis yml
- problem sovled
- one job per task, no reuse of jobs
- stop clicking, write code
- in startups you can get quite introverted
- when i screwed up, i’d write it down
- but it lived in a notebook and i never went back and looked at it
- i started bluetacking the notes to the wall
- “when you change an interface you will screw somebody”
- “if something is missing it might be NOT BEING CREATED or BEING REMOVED”
- visible to all:
- visitors
- friends
- hot deskers
- consultants
- other companies
- potential hires
- prompts for conversations
- passively consumable
- lo-fi and approachable
- no sense of authority
- you can interact with them
- add updates
- what started as a means for self-improvement became a shift in culture
- distributed? asynchronous?
- “when you find yourself trying to ‘JUST MAKE IT WORK’ you probably don’t understand the problem
- wikis?
- where content goes to die
- tweets?
- no context
- noone will subscribe to my newsletter
- “it’ll all be okay once <big thing comes> is almost never true”
- low tech solutions start balls rolling faster
- sarah wells @sarahjwells
- FT
- a nudge is a means of encouraging or guiding behaviour
- canonical example: urinals with picture of a fly
- encourages better aiming, reduces cleaning costs
- TfL posters to encourage people to avoid main stations
- devops: you build it, you run it
- teams should be empowered
- to choose their own technology
- but it’s costly if everyone does their own thing
- we want people to do common things
- we can’t tell them they have to do it
- can we nudge them?
- teams should be empowered
- make it easy
- make a good default, make it easy
- engineering checklist
- tells you what to do, not how to do it
- but comes with default suggestions
- make it attractive
- people should see the benefit up front
- they can see short-term costs & benefits
- healthcheck standard
- libraries that make it easy
- lots of tooling around it
- you can easily get added to an operational status board
- social aspects
- we are influenced by our peers
- AWS costs
- can see how other teams are doing compared to your own
- timely
- communicate what you’ll provide and when
- this is about realising your own developers are also your clients
- you don’t have a captive market
- you’re competing with external providers and services
- but: you should have a massive advantage
- your thing only needs to work within your org’s context
- I did a longer version of this talk earlier (slides)
- Ebru Cucen @ebrucucen
- I’m a .net dev turned devops
- platform engineer right now
- “leaky pipeline”: decline of involvement and retention of women
in tech
- lack of mentors
- 6% women in devops (according to state of devops report)
- interviews
- require half a day
- childcare?
- extra preparation to get over pregnancy
- memory loss
- require half a day
- workplace
- ask for help
- can’t have a phone call in middle of night when baby is sick
- physical and mental load
- sharing night shift
- consesnus on rules between parents first
- sharing activities
- chores @ home
- deliveries & subscriptions
- meetups
- leisure deficit?
- women have less leisure time when they become parents
- why do women leave?
- unfriendly work-family practices
- ..some others..
- opt-out or squeezed out?
- how to stop?
- welcome women back
- alumni programs
- encourage male participation in family-friendly benefits
- change the long hours norm
- establish family-friendly HR practices
- can the interviews be paid?
- can devops role
- allow one day wfh?
- allow 6 hour days?
- 3 day weeks?
- how can you look after yourself?
- go for a walk
- have lunch on your own to get some headspace
- one to ones at a place a 10 minute walk away
- we did a lot of talking on the walk itself
- the problem with getting isolation is you’re isolated
- I’m a consultant, I spend a lot of time on the road and on my own in the evenings
- i need people around me to get out of that funk
- how many people have a “work persona”? (~60% hands go up)
- i used to spend 70% time travelling. completely messed up my mental health
- fight or flight - or freeze?
- when travelling
- want to get away from people during the day
- but evenings and breakfasts can be quite lonely
- has anyone got senior management buy-in to have structures in place to support people’s mental health?
- Equality Act
- particularly if you have a long-term mental health issue
- business has to make reasonable adjustments
- mental health comes under the “disability” protected characteristic in the law
- HR - they’re nice people but they have to protect the company
- if you have all these structures in place, how do you give
feedback to someone who suffers from depression who is also,
through their behaviour, getting the rest of their team down?
- giving effective feedback from manager-tools podcast
- HR are in to a difficult position
- our HR team calls themselves the people team
- to send the message that they’re there for you
- I had someone who was off with stress once
- I had no personal experience with this
- I found it difficult to empathise - i didn’t comprehend
- HR only said “listen and be sympathetic”
- I had no idea what to say on the phone
- he said he’d gone off with stress and anxiety
- now: stomach problems & migraines
- I remember saying “you’re properly ill aren’t you”
- it sent the message: physical illness is “proper”
- I wanted more solid advice
- when my lead showed confidence and trust in me despite my mental health, it made such a difference. I got better much faster than in periods when
- Miscarriage association: simply say campaign
- Mind and Calm have similar and great resources
- OSMI forums (formerly devpressed)
- 35 dumb things well-intentioned people say
- few of us have formal training in these things
- we use a company called Canada Life for face-to-face counselling sessions
- are there services like this for contractors?
- i think BUPA offer it
- we saw very little usage until we changed the posters to make it clear that people could contact company direct - HR wouldn’t know
- line management training
- i don’t want to scare people off with a huge pile of training that people have to do before they can do any line management
- but i want line managers to be really good at supporting people
- I’m a junior and I career-switched
- from a 90%-women industry to a 90%-men industry
- I find it hard to tell what’s normal and what’s ok
- my first year i was on a program switching every few months
- second placement: tech lead would not talk to me
- super stressful
- “you just need to change your attitude”
- “you need to force him to engage”
- from line manager of all people!
- a bit of a boy’s club
- they didn’t want to address the problem
- they made it my problem
- second placement: tech lead would not talk to me
- this was a group discussion. we had 2 self-identified frontend developers (one “pure” frontend, one “full stack”, my terms not theirs!), and few backend developers / ops / SREs.
- these notes were written after the fact based on what we wrote up
on the flipchart
- they therefore have my personal spin and embellishments on them
With that in mind, here is what we discussed:
- UX for internal tools
- often this really sucks!
- web interfaces built by platform engineers are often (barely) functional but confusing and terrible
- metaphors between technologies
- CSS is a bit like Puppet
- they are both declarative
- they both have complex dependency graphs
- in puppet, dependencies are explicit; in CSS they are implicit and confusing
- there are module systems for both, but often a piece within one module can interact unexpectedly with a piece within another module, showing that the modules don’t offer isolation/encapsulation
- React is a bit like Terraform
- React works on the DOM, Terraform works on AWS (and other providers)
- they have the same philosophy:
- stop mutating things in place!
- declare how you want your system to be, and the tool will work out the changes between current state and desired state and compute the minimal set of mutating operations to get to the desired state
- the Virtual DOM is like the terraform statefile
- an idealized record of the previous state, optimized to be able to compute fast diffs locally without making expensive queries to the “real world” (DOM or AWS)
- they have similar pitfalls:
- if an external actor (other JS or other AWS consumer) mutates the state without React/terraform’s knowledge, it can get confused
- this feels like a bigger risk in terraform?
- can terraform learn from react? can react learn from terraform?
- CSS is a bit like Puppet
- caches
- we have squid, varnish, CDNs, etc
- but: the browser has Service Workers
- application-aware caching
- can be much more effective
- can I have one of these on the backend please?
- is varnish ESL good enough here?
- offline first
- while we weren’t looking, frontend developers became distributed
systems designers
- and they’re quite good at it too
- they are already used to asynchronous programming
- the “offline first” movement is providing tools to cope with periods of unavailability
- offline first technology
- service workers
- background sync API
- pouchDB / indexedDB
- functional JS / promises / futures
- these have wider applicability but they’re really helpful here
- can we have “offline first” client libraries?
- circuit breakers (popularized by Release It!, which has just released its second edition!)
- request budgets
- the actor model
- the only form of communication is asynchronous
- you have to cope with failure as a matter of course
- erlang
- “let it crash”
- auto healing mechanisms
- clean separation of business logic code from error handling code
- question: is http still the answer?
- http is fundamentally synchronous, but actors (and distributed systems) are asynchronous
- gRPC, erlang messages, …?
- while we weren’t looking, frontend developers became distributed
systems designers
There was an interesting a-ha moment where the “pure” frontend developer asked: “so do you backend developers program synchronously all the time then? oohhh, I’m starting to understand where you are coming from now!”
I think it’s really interesting that frontend developers have, through necessity, embraced asynchronous programming to a much greater extent than backend developers.