An Optimistic Perspective on Offline Reinforcement Learning
https://ai.googleblog.com/2020/04/an-optimistic-perspective-on-offline.html
- This is still work in progress, follow this Gist if you are interested in the topic


See animated version here
An Optimistic Perspective on Offline Reinforcement Learning
https://ai.googleblog.com/2020/04/an-optimistic-perspective-on-offline.html
See animated version here
There are two RL Paradigms
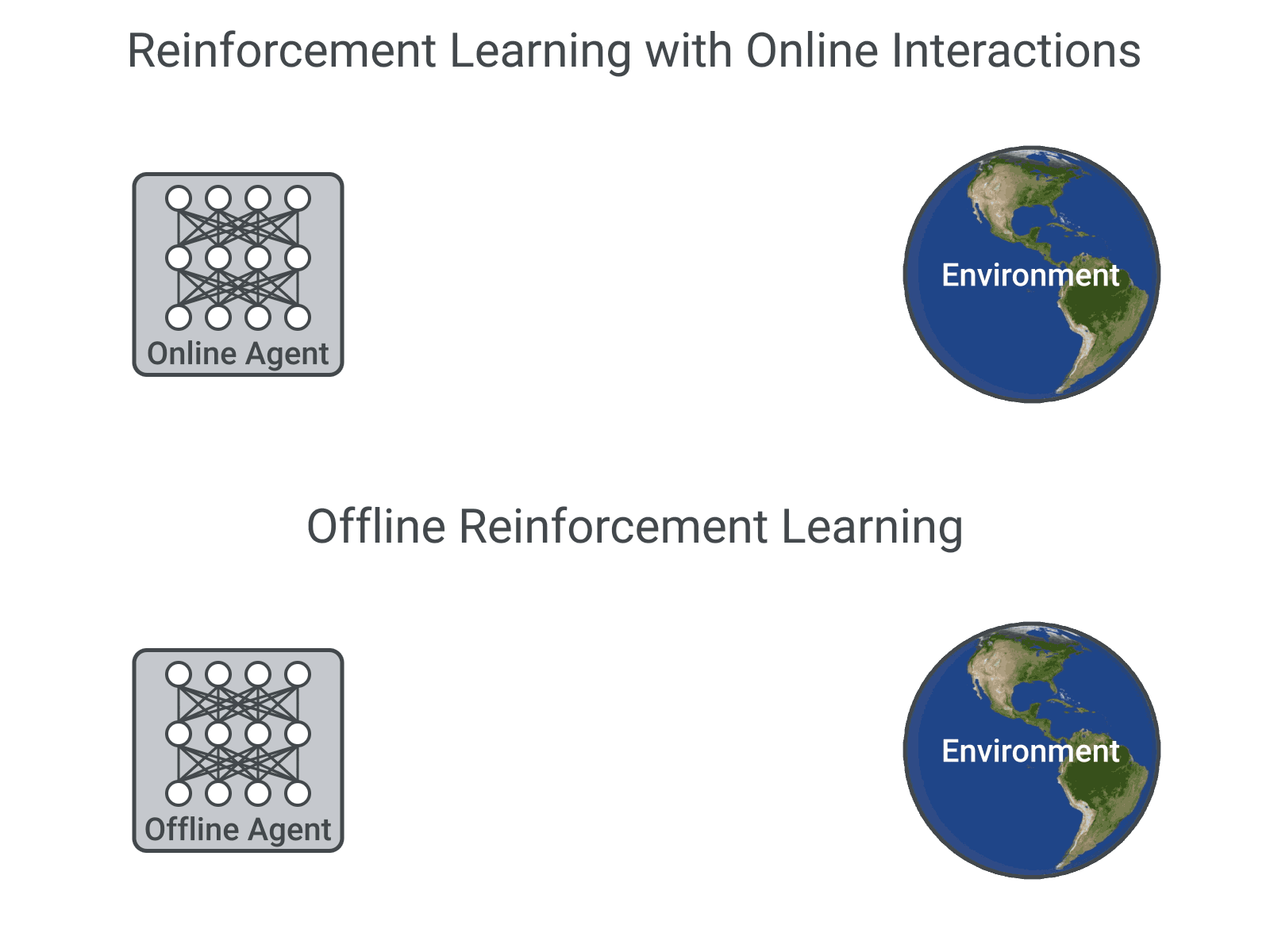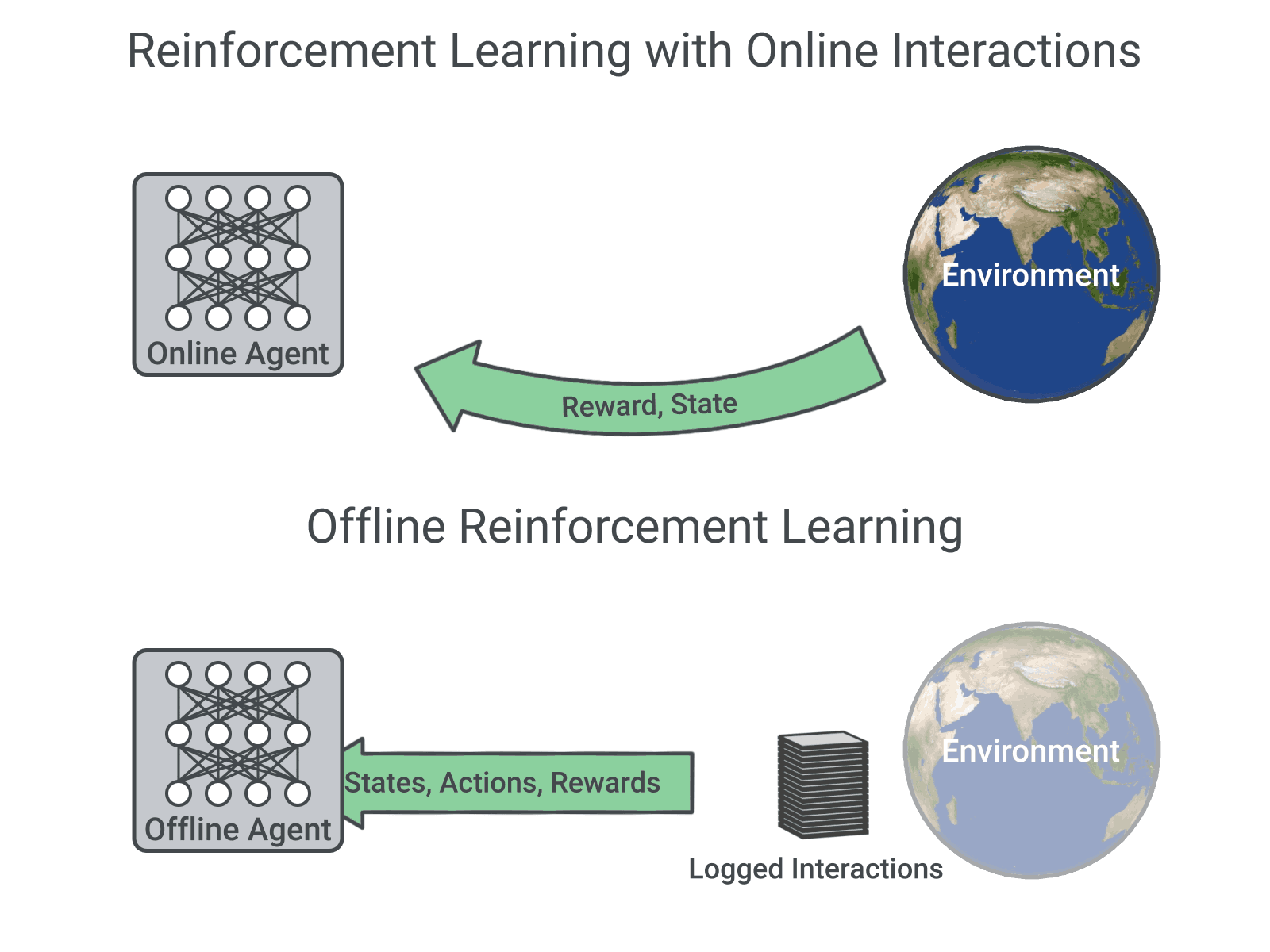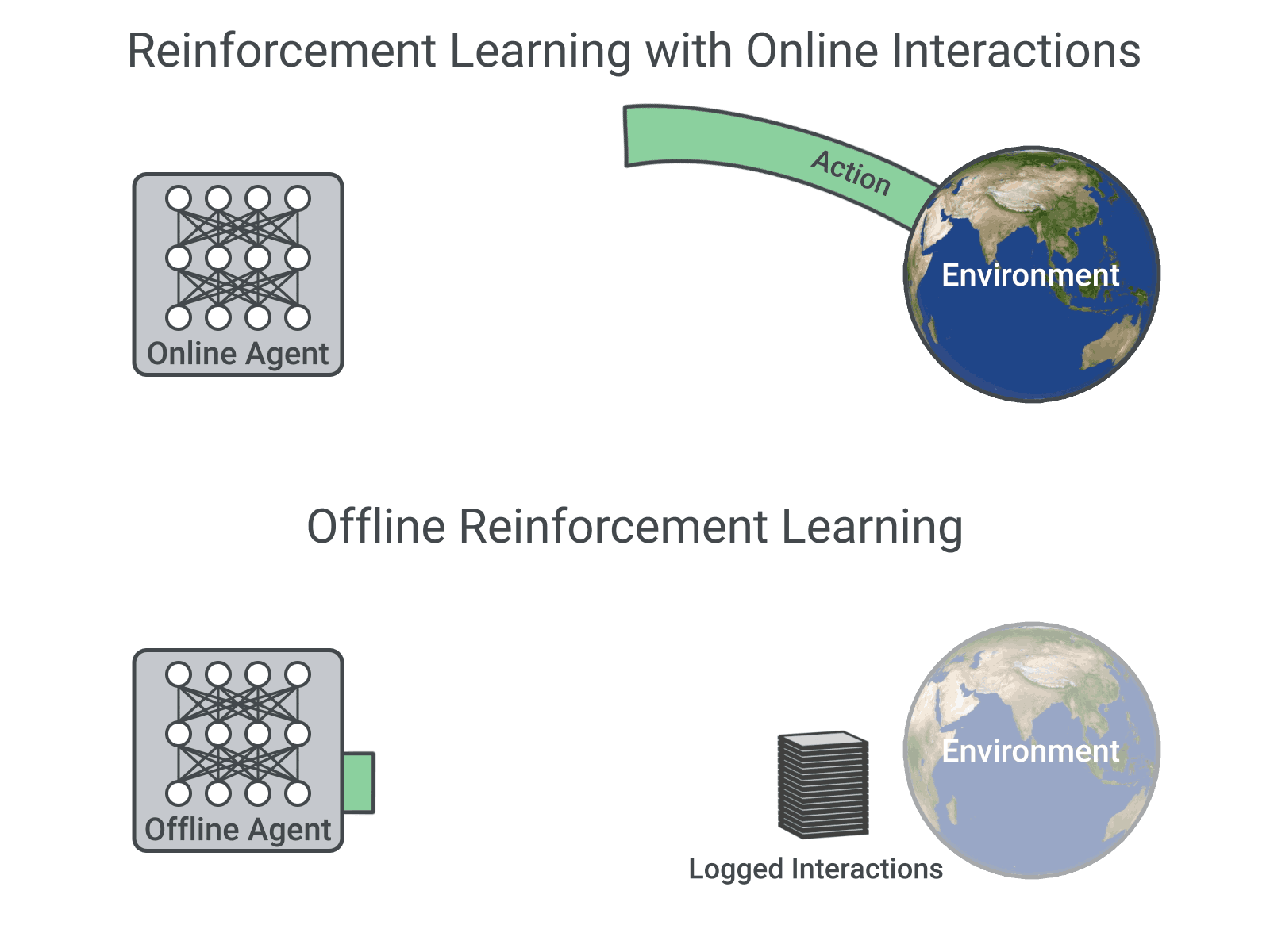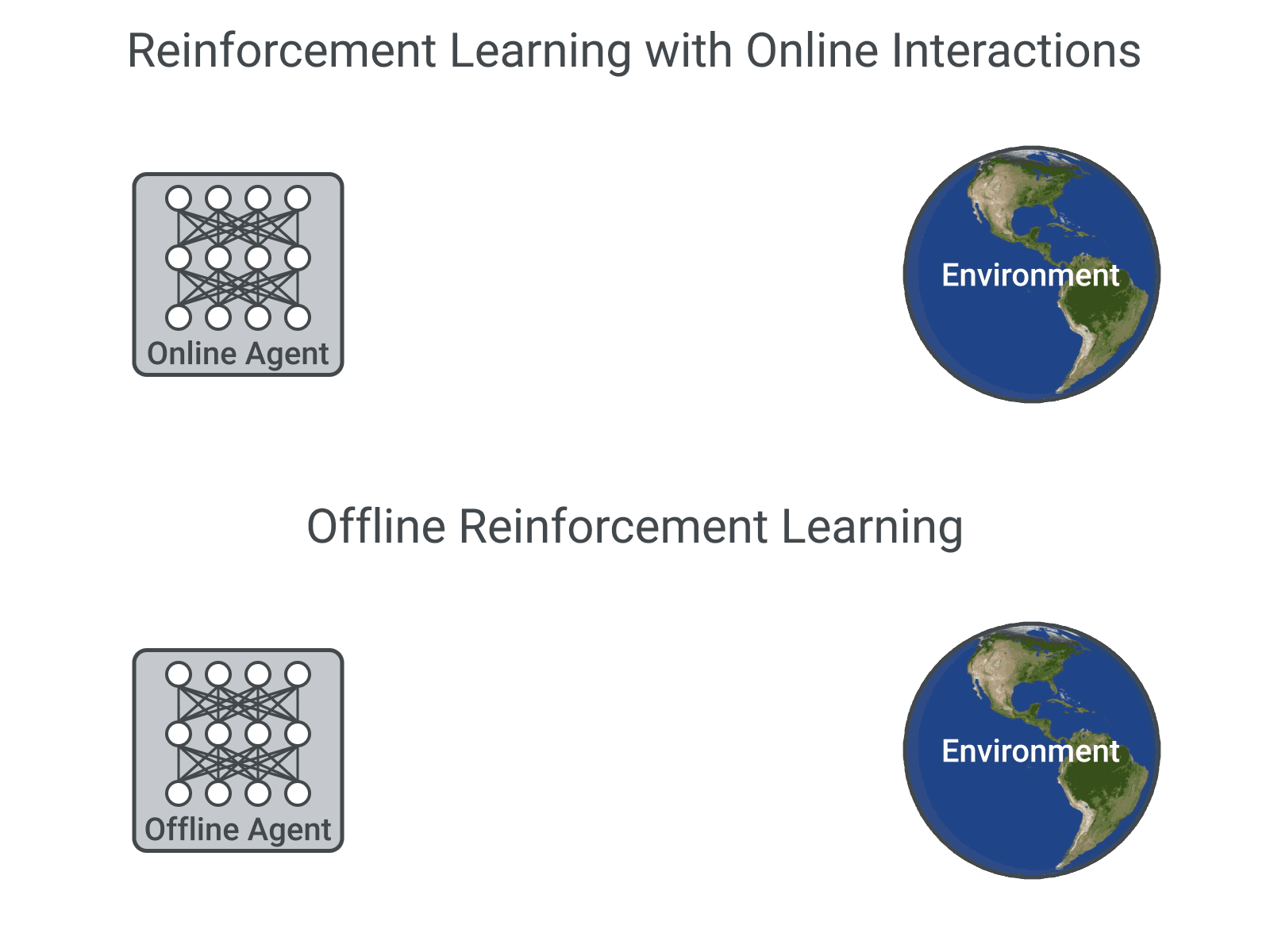
the Online RL consists of learning by interacting with the environment which means all the observations come from the best policy which is the policy obtained by updating the policy with the new observations as soon as they are available so it works like this
 is used to observe
is used to observe 

the Offline RL or Batch RL is radically different from the previous approach as the policy update happens in a batch mode which means
is used to collect a batch of N observations 
 means all these observations are related to
means all these observations are related to 
The latter method is generalized in Off Policy RL where the exploration policy(ies) hence mainly aimed at data collection are different from the exploitation policy
{kind=link}
Overview (Latex All the Things Version)
How is it possible to categorize RL at a very high level
There are two RL Paradigms
the Online RL consists of learning by interacting with the environment which means all the observations come from the best policy which is the policy obtained by updating the policy with the new observations as soon as they are available so it works like this
the Offline RL or Batch RL is radically different from the previous approach as the policy update happens in a batch mode which means
The latter method is generalized in Off Policy RL where there is a distinction between
This framework allows the agent to learn a policy without any interaction at all, using just a dataset of previously collected experiences