Maybe you've heard about this technique but you haven't completely understood it, especially the PPO part. This explanation might help.
We will focus on text-to-text language models 📝, such as GPT-3, BLOOM, and T5. Models like BERT, which are encoder-only, are not addressed.
Reinforcement Learning from Human Feedback (RLHF) has been successfully applied in ChatGPT, hence its major increase in popularity. 📈
RLHF is especially useful in two scenarios 🌟:
- You can’t create a good loss function
- Example: how do you calculate a metric to measure if the model’s output was funny?
- You want to train with production data, but you can’t easily label your production data
- Example: how do you get labeled production data from ChatGPT? Someone needs to write the correct answer that ChatGPT should have answered
RLHF algorithm ⚙️:
- Pretraining a language model (LM)
- Training a reward model
- Fine-tuning the LM with RL
In this step, you need to either train one language model from scratch or just use a pretrained one like GPT-3.
Once you have that pretrained language model, you can also do an extra optional step, called Supervised Fine-Tuning (STF). This is nothing more than getting some human-labeled (input, output) text pairs and fine-tuning the language model you have. STF is considered high-quality initialization for RLHF.
At the end of this step, we end up with our trained LM which is our main model, and the one we want to train further with RLHF.

Figure 1: Our pretrained language model.
In this step, we are interested in collecting a dataset of (input text, output text, reward) triplets.
In Figure 2, there's a representation of the data collection pipeline: using input text data (if production data, better), pass it through your model, and have a human attribute a reward to the generated output text.

Figure 2: Pipeline to collect data for reward model training.
The reward is usually an integer between 0-5, but it can be a simple 0/1 in a 👍/👎 experience.
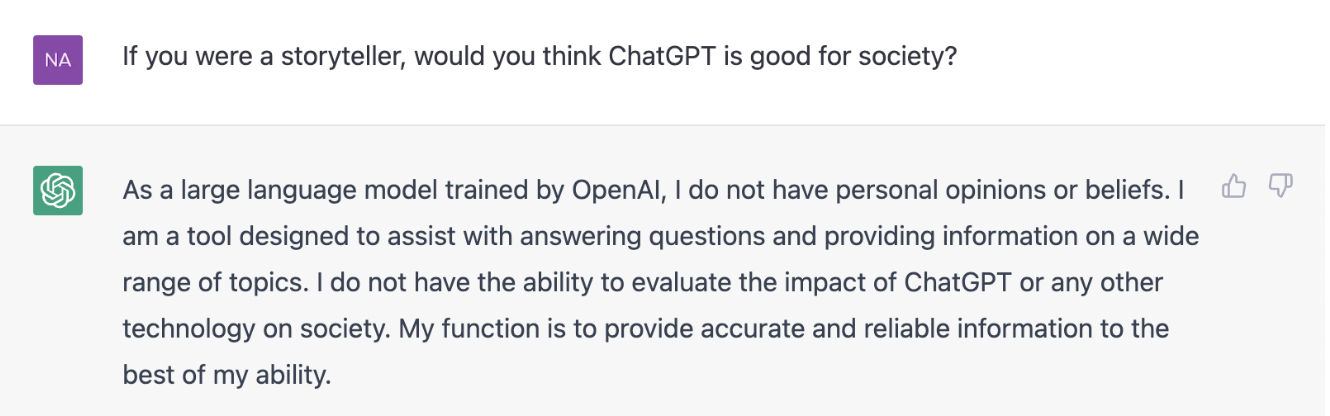
Figure 3: Simple 👍/👎 reward collection in ChatGPT.

Figure 4: A more complete reward collection experience: the model outputs two texts and the human has to choose which one was better, and also give an overall rating with comments.
With this new dataset, we will train another language model to receive the (input, output) text and return a reward scalar! This will be our reward model.
The main objective here is to use the reward model to mimic the human's reward labeling and therefore be able to do RLHF training offline, without the human in the loop.

Figure 5: The trained reward model, that will mimic the rewards given by humans.
It's in this step that magic really happens and RL comes into play.
The objective of this step is to use the rewards given by the reward model to train the main model, your trained LM. However, since the reward will not be differentiable, we will need to use RL to be able to construct a loss that we can backpropagate to the LM.

Figure 6: Fine-tuning the main LM using the reward model and the PPO loss calculation.
At the beginning of the pipeline, we will make an exact copy of our LM and freeze its trainable weights. This copy of the model will help to prevent the trainable LM from completely changing its weights and starting outputting gibberish text to fool the reward model.
That is why we calculate the KL divergence loss between text output probabilities of both the frozen and non-frozen LM.
This KL loss is added to the reward that is produced by the reward model. Actually, if you are training your model while in production (online learning), you can replace this reward model with the human reward score directly. 💡
Having your reward and KL loss, we can now apply RL to make the reward loss differentiable.
Why isn't the reward differentiable? Because it was calculated with a reward model that received text as input. This text is obtained by decoding the output log probabilities of the LM. This decoding process is non-differentiable.
To make the loss differentiable, finally Proximal Policy Optimization (PPO) comes into play! Let's zoom in.

Figure 7: Zoom-in on the RL Update box - PPO loss calculation.
The PPO algorithm calculates a loss (that will be used to make a small update on the LM) like this:
- Make "Initial probs" equal to "New probs" to initialize.
- Calculate a ratio between the new and initial output text probabilities.
- Calculate the loss given the formula
loss = -min(ratio * R, clip(ratio, 0.8, 1.2) * R), whereRis thereward + KL(or a weighted average like0.8 * reward + 0.2 * KL) previously computed andclip(ratio, 0.8, 1.2)is just bounding the ratio to be0.8 <= ratio <= 1.2. Note that 0.8/1.2 are just commonly used hyperparameter values that are simplified here. Also not that we want to maximize the reward, that's why we add the minus-, so that we minimize the negation of the loss with gradient descent. - Update the weights of the LM by backpropagating the loss.
- Calculate the "New probs" (i.e., new output text probabilities) with the newly updated LM.
- Repeat from step 2 up to N times (usually, N=4).
That's it, this is how you use RLHF in text-to-text language models!
Things can get more complicated because there are also other losses that you can add to this base loss that I presented, but this is the core implementation.
"the desired token's probability" - but there isn't such a thing, right? There's only a reward score, there is no target output text in this setup